Agenta
Agenta is the open-source LLMOps platform for centralized prompt management and team collaboration.
Visit
About Agenta
Agenta is the open-source LLMOps platform engineered to bring order and reliability to the inherently unpredictable process of building with large language models. It serves as a centralized hub for AI development teams, bridging the critical gap between rapid experimentation and production-grade deployment. The platform is designed for a collaborative ecosystem, empowering not just AI developers but also product managers and subject matter experts to contribute directly to the LLM development lifecycle. Agenta directly tackles the fragmented workflows that plague modern AI teams—where prompts are lost across communication tools, evaluations are ad-hoc, and debugging production issues is a game of guesswork. By integrating prompt management, systematic evaluation, and comprehensive observability into a single, unified platform, Agenta provides the structured processes and tools necessary to follow LLMOps best practices. Its core value proposition is enabling teams to experiment faster, evaluate with evidence, and ship high-quality, reliable LLM applications with confidence and transparency.
Features of Agenta
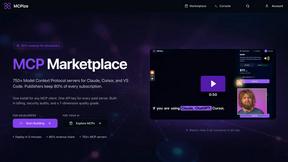
Unified Playground & Versioning
Agenta provides a centralized playground where teams can experiment with different prompts, parameters, and foundation models from various providers in a side-by-side comparison. Every iteration is automatically versioned, creating a complete audit trail of changes. This model-agnostic approach prevents vendor lock-in and ensures that the entire team has a single source of truth for every experiment, eliminating the chaos of scattered prompts across emails and spreadsheets.
Systematic Evaluation Framework
Move beyond "vibe testing" with Agenta's robust evaluation system. It allows teams to create a systematic process for running experiments, tracking results, and validating every change before deployment. The platform supports any evaluator, including LLM-as-a-judge, custom code, and built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
Gain deep visibility into your live LLM applications. Agenta traces every request, allowing developers to pinpoint exact failure points when issues arise. Teams can annotate these traces collaboratively or gather direct user feedback. A powerful feature enables turning any problematic production trace into a test case with a single click, closing the feedback loop and using real-world data to prevent future regressions through live, online evaluations.
Cross-Functional Collaboration Tools
Agenta breaks down silos by providing tailored interfaces for every team member. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the UI, while developers work via a full-featured API. This parity between UI and API workflows brings PMs, experts, and developers into one cohesive, efficient development process.
Use Cases of Agenta
Streamlining Enterprise LLM Application Development
Large organizations with cross-functional teams use Agenta to centralize their LLM development workflow. It coordinates efforts between AI engineers writing the code, product managers defining requirements, and subject matter experts ensuring accuracy. By providing a shared platform for experimentation, evaluation, and debugging, it significantly reduces time-to-market for internal or customer-facing LLM applications while improving final quality and reliability.
Implementing Rigorous LLM Evaluation & Testing
Teams transitioning from prototype to production employ Agenta to establish a rigorous, evidence-based testing regime. They use it to create benchmark test sets, run automated evaluations across multiple model and prompt variants, and integrate human-in-the-loop reviews. This use case is critical for applications where accuracy, safety, or consistency are paramount, ensuring every update is a verified improvement, not a regression.
Debugging Complex AI Agents in Production
When a deployed AI agent or complex chain exhibits unexpected behavior, developers use Agenta's observability features to diagnose the issue. By examining detailed traces of each step in the agent's reasoning, they can isolate the exact point of failure—whether it's a specific prompt, a tool call, or a model response. The ability to save errors directly from production into a test set accelerates the fix-and-validate cycle.
Managing Prompts at Scale with Governance
Companies deploying multiple LLM features across different products utilize Agenta as a system of record for prompt management. It prevents "prompt sprawl" by versioning all prompts, tracking their performance through evaluations, and controlling their deployment. This provides essential governance, auditability, and the ability to roll back changes confidently, which is crucial for maintaining standards in regulated or large-scale environments.
Frequently Asked Questions
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, allowing users to review, contribute, and self-host the entire platform. This open model ensures transparency, avoids vendor lock-in, and allows the tool to be customized and integrated deeply into your existing infrastructure and workflows.
How does Agenta integrate with existing AI frameworks?
Agenta is designed to be framework-agnostic and integrates seamlessly with popular ecosystems. It works natively with chains built using LangChain, LlamaIndex, and other orchestration frameworks. Furthermore, it supports models from any provider (OpenAI, Anthropic, Cohere, open-source models, etc.), allowing you to incorporate Agenta's management, evaluation, and observability layers without rewriting your application.
Can non-technical team members really use Agenta effectively?
Absolutely. A key design principle of Agenta is to democratize the LLM development process. The platform provides an intuitive web UI that allows product managers and domain experts to safely edit prompts, run experiments in the playground, configure evaluations, and review results—all without writing a single line of code. This bridges the gap between technical implementation and domain expertise.
What does Agenta's observability provide that standard logging does not?
While logging captures events, Agenta's observability is purpose-built for LLMs. It captures the full reasoning trace of complex agents, including intermediate steps, tool calls, and context. This structured trace data is immediately queryable and actionable, allowing you to annotate failures, calculate metrics per step, and instantly convert any trace into a reproducible test case, enabling a closed-loop debugging system that standard logs cannot offer.
Pricing of Agenta
Agenta is an open-source platform, and the core software is available for free under an open-source license. This allows for unlimited self-hosting and use. For teams seeking a managed, cloud-hosted service with additional enterprise features and support, Agenta offers commercial plans. Detailed pricing tiers, specific features included in each plan, and cost information are available directly on the Agenta website. You can explore these options and contact their team to book a demo or discuss specific enterprise requirements.
Explore more in this category:
Similar to Agenta
HypeShare
Secure file transfer platform for sending large files fast — no signup required, end-to-end encryption, up to 10GB free.
JustLaunched
The launch platform for indie makers — schedule your launch, get in front of buyers, and blast across directories.
Bank Statement Engine
Free tool to convert PDF bank statements to Excel, CSV, JSON, QBO, OFX and QIF. No signup, no limits.
TheToolsVerse
TheToolsVerse is an AI tools directory that helps users discover, compare, and find the best AI tools for productivity, content creation, coding, mark
Photo3D
AI photo-to-3D workspace for GLB-ready asset drafts, browser previews, and practical 3D file preparation tools.