Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
Agenta is the open-source LLMOps platform for centralized prompt management and team collaboration.
Last updated: March 1, 2026
OpenMark AI benchmarks over 100 LLMs for your specific tasks, delivering fast, cost-effective, and reliable results without setup hassles.
Last updated: March 26, 2026
Visual Comparison
Agenta
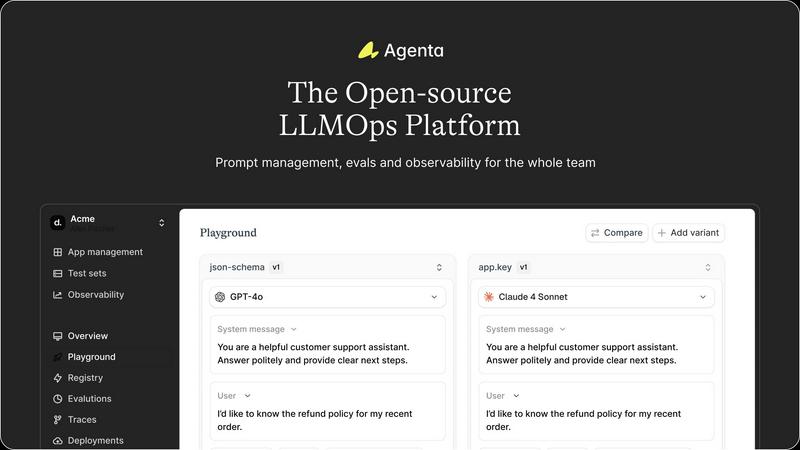
OpenMark AI

Feature Comparison
Agenta
Unified Playground & Versioning
Agenta provides a centralized playground where teams can experiment with different prompts, parameters, and foundation models from various providers in a side-by-side comparison. Every iteration is automatically versioned, creating a complete audit trail of changes. This model-agnostic approach prevents vendor lock-in and ensures that the entire team has a single source of truth for every experiment, eliminating the chaos of scattered prompts across emails and spreadsheets.
Systematic Evaluation Framework
Move beyond "vibe testing" with Agenta's robust evaluation system. It allows teams to create a systematic process for running experiments, tracking results, and validating every change before deployment. The platform supports any evaluator, including LLM-as-a-judge, custom code, and built-in metrics. Crucially, you can evaluate the full trace of an agent's reasoning, not just the final output, and seamlessly integrate human feedback from domain experts into the evaluation workflow.
Production Observability & Debugging
Gain deep visibility into your live LLM applications. Agenta traces every request, allowing developers to pinpoint exact failure points when issues arise. Teams can annotate these traces collaboratively or gather direct user feedback. A powerful feature enables turning any problematic production trace into a test case with a single click, closing the feedback loop and using real-world data to prevent future regressions through live, online evaluations.
Cross-Functional Collaboration Tools
Agenta breaks down silos by providing tailored interfaces for every team member. It offers a safe, no-code UI for domain experts to edit and experiment with prompts. Product managers and experts can run evaluations and compare experiments directly from the UI, while developers work via a full-featured API. This parity between UI and API workflows brings PMs, experts, and developers into one cohesive, efficient development process.
OpenMark AI
Intuitive Task Configuration
OpenMark AI offers an intuitive task configuration feature that allows users to easily describe the tasks they want to benchmark. This simplicity ensures that users can quickly set up tests without extensive technical knowledge, making it accessible for teams of all skill levels.
Real-Time Model Comparison
The platform facilitates real-time comparisons of over 100 models, enabling users to see how different models perform against the same task. This feature provides side-by-side results derived from actual API calls, ensuring that users are making informed decisions based on real-world performance rather than theoretical claims.
Cost and Latency Analysis
OpenMark AI provides detailed insights into the cost per request and latency of each model tested. This analysis allows users to gauge not only the financial implications of their choices but also the speed at which each model can deliver results, thus optimizing budget and performance.
Consistency Evaluation
With OpenMark AI, users can assess the consistency of model outputs by running the same task multiple times. This feature is crucial for teams looking to ensure that their chosen model will produce reliable results, thereby enhancing the overall quality of their AI applications.
Use Cases
Agenta
Streamlining Enterprise LLM Application Development
Large organizations with cross-functional teams use Agenta to centralize their LLM development workflow. It coordinates efforts between AI engineers writing the code, product managers defining requirements, and subject matter experts ensuring accuracy. By providing a shared platform for experimentation, evaluation, and debugging, it significantly reduces time-to-market for internal or customer-facing LLM applications while improving final quality and reliability.
Implementing Rigorous LLM Evaluation & Testing
Teams transitioning from prototype to production employ Agenta to establish a rigorous, evidence-based testing regime. They use it to create benchmark test sets, run automated evaluations across multiple model and prompt variants, and integrate human-in-the-loop reviews. This use case is critical for applications where accuracy, safety, or consistency are paramount, ensuring every update is a verified improvement, not a regression.
Debugging Complex AI Agents in Production
When a deployed AI agent or complex chain exhibits unexpected behavior, developers use Agenta's observability features to diagnose the issue. By examining detailed traces of each step in the agent's reasoning, they can isolate the exact point of failure—whether it's a specific prompt, a tool call, or a model response. The ability to save errors directly from production into a test set accelerates the fix-and-validate cycle.
Managing Prompts at Scale with Governance
Companies deploying multiple LLM features across different products utilize Agenta as a system of record for prompt management. It prevents "prompt sprawl" by versioning all prompts, tracking their performance through evaluations, and controlling their deployment. This provides essential governance, auditability, and the ability to roll back changes confidently, which is crucial for maintaining standards in regulated or large-scale environments.
OpenMark AI
Model Selection for Product Features
Teams can leverage OpenMark AI to determine the most appropriate AI model for specific product features. By benchmarking various models against the same tasks, they can identify which model aligns best with their quality and cost requirements before launch.
Research and Development
Researchers can utilize OpenMark AI to evaluate how different models handle complex queries. This helps in selecting the right model for experimental applications or new features in AI systems, ensuring that the research is built on solid foundations.
Quality Assurance in AI Deployments
Quality assurance teams can employ OpenMark AI to validate model outputs before deployment. By comparing the performance of multiple models, they can ensure that the end-user experience remains consistent and meets quality standards.
Cost Management in AI Operations
Organizations focused on managing costs associated with AI operations can use OpenMark AI to analyze the cost-effectiveness of different models. This insight allows them to optimize their spending while still achieving desired performance levels.
Overview
About Agenta
Agenta is the open-source LLMOps platform engineered to bring order and reliability to the inherently unpredictable process of building with large language models. It serves as a centralized hub for AI development teams, bridging the critical gap between rapid experimentation and production-grade deployment. The platform is designed for a collaborative ecosystem, empowering not just AI developers but also product managers and subject matter experts to contribute directly to the LLM development lifecycle. Agenta directly tackles the fragmented workflows that plague modern AI teams—where prompts are lost across communication tools, evaluations are ad-hoc, and debugging production issues is a game of guesswork. By integrating prompt management, systematic evaluation, and comprehensive observability into a single, unified platform, Agenta provides the structured processes and tools necessary to follow LLMOps best practices. Its core value proposition is enabling teams to experiment faster, evaluate with evidence, and ship high-quality, reliable LLM applications with confidence and transparency.
About OpenMark AI
OpenMark AI is a cutting-edge web application designed for task-level benchmarking of large language models (LLMs). It allows users to articulate their testing requirements in plain language, facilitating seamless comparisons between various AI models in a single session. By evaluating factors such as cost per request, latency, scored quality, and stability across multiple runs, OpenMark AI provides users with a comprehensive understanding of model performance beyond mere luck-based outputs. This product caters specifically to developers and product teams who need to validate and select the right AI model prior to deploying an AI feature. With hosted benchmarking that utilizes credits, users can avoid the hassle of configuring multiple API keys for different models, streamlining the testing process. OpenMark AI emphasizes cost efficiency, helping teams assess the quality of outputs relative to their expenditure, rather than just the cheapest token prices found in marketing materials. It supports an extensive range of models and is focused on aiding pre-deployment decisions, allowing users to determine the best fit for their workflows, associated costs, and output consistency. Free and paid plans are available, ensuring that teams can find an option suited to their needs.
Frequently Asked Questions
Agenta FAQ
Is Agenta truly open-source?
Yes, Agenta is a fully open-source platform. The core codebase is publicly available on GitHub, allowing users to review, contribute, and self-host the entire platform. This open model ensures transparency, avoids vendor lock-in, and allows the tool to be customized and integrated deeply into your existing infrastructure and workflows.
How does Agenta integrate with existing AI frameworks?
Agenta is designed to be framework-agnostic and integrates seamlessly with popular ecosystems. It works natively with chains built using LangChain, LlamaIndex, and other orchestration frameworks. Furthermore, it supports models from any provider (OpenAI, Anthropic, Cohere, open-source models, etc.), allowing you to incorporate Agenta's management, evaluation, and observability layers without rewriting your application.
Can non-technical team members really use Agenta effectively?
Absolutely. A key design principle of Agenta is to democratize the LLM development process. The platform provides an intuitive web UI that allows product managers and domain experts to safely edit prompts, run experiments in the playground, configure evaluations, and review results—all without writing a single line of code. This bridges the gap between technical implementation and domain expertise.
What does Agenta's observability provide that standard logging does not?
While logging captures events, Agenta's observability is purpose-built for LLMs. It captures the full reasoning trace of complex agents, including intermediate steps, tool calls, and context. This structured trace data is immediately queryable and actionable, allowing you to annotate failures, calculate metrics per step, and instantly convert any trace into a reproducible test case, enabling a closed-loop debugging system that standard logs cannot offer.
OpenMark AI FAQ
How does OpenMark AI ensure unbiased benchmarking?
OpenMark AI runs real API calls to models, avoiding cached or marketing-sourced data. This method guarantees that users receive unbiased, actual performance metrics for each model tested.
Can I benchmark models from different providers?
Yes, OpenMark AI supports a wide catalog of models from various providers, including OpenAI, Anthropic, and Google, allowing for comprehensive comparisons across different platforms without the need for multiple API keys.
Is there a limit to the number of tasks I can benchmark?
While there are no strict limits, the number of active tasks you can run simultaneously may depend on your selected plan. Users can manage tasks efficiently within the application to maximize benchmarking opportunities.
What types of models can I compare with OpenMark AI?
OpenMark AI supports a diverse range of models across various AI tasks, including classification, translation, data extraction, and more, enabling users to find the best fit for their specific use cases.
Alternatives
Agenta Alternatives
Agenta is an open-source LLMOps platform designed to centralize the development, evaluation, and management of large language model applications. It falls within the category of development tools aimed at AI and machine learning teams, helping them collaborate and streamline workflows for more reliable LLM outputs. Users often explore alternatives to find a solution that aligns perfectly with their specific needs. This search can be driven by factors such as budget constraints, the requirement for different feature sets like advanced monitoring or native integrations, or the need for a platform that is either fully managed or self-hosted. The ideal tool varies based on team size, technical expertise, and project complexity. When evaluating other platforms, key considerations include the depth of collaboration features, the robustness of evaluation and testing frameworks, and the overall approach to observability and prompt management. The goal is to find a system that not only manages prompts but also brings structure, transparency, and efficiency to the entire LLM application lifecycle.
OpenMark AI Alternatives
OpenMark AI is a web application designed for task-level benchmarking of large language models (LLMs). It allows developers and product teams to evaluate over 100 models based on key performance metrics such as cost, speed, quality, and stability, making it essential for pre-deployment decisions regarding AI features. Users often seek alternatives to OpenMark AI for various reasons, including pricing structures, feature sets, and specific platform requirements that may better suit their needs. When choosing an alternative, consider factors like integration capabilities, the robustness of benchmarking features, and the availability of support to ensure that you select a solution that aligns with your project goals.