diffray vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.
diffray
Diffray delivers AI-driven code reviews with over 30 agents to identify real bugs and reduce false positives.
Last updated: February 28, 2026
OpenMark AI benchmarks 100+ LLMs on your task: cost, speed, quality & stability. Browser-based; no provider API keys for hosted runs.
Visual Comparison
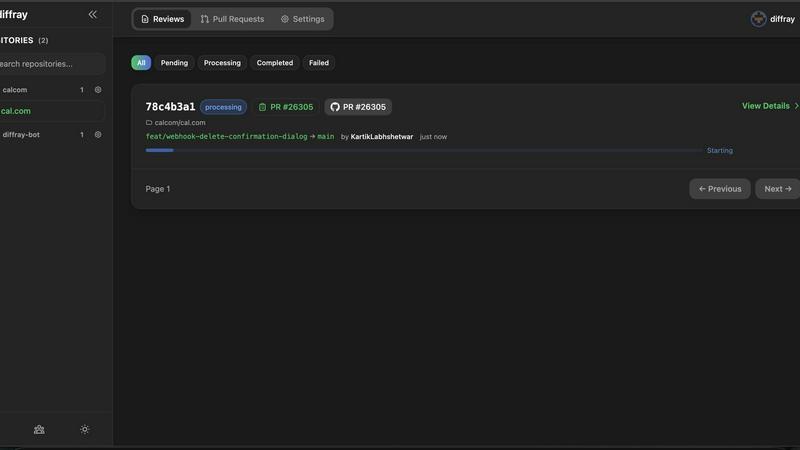
diffray
OpenMark AI

Overview
About diffray
diffray is an advanced AI-driven code review tool that revolutionizes the code review process for development teams. It is designed to improve both the efficiency and accuracy of code assessments by leveraging a unique multi-agent architecture. Unlike conventional review tools that utilize a single, generic model, diffray consists of over 30 specialized agents, each focusing on distinct aspects of code quality, including security vulnerabilities, performance issues, bug detection, adherence to best practices, and SEO optimization. This sophisticated approach leads to a significantly more nuanced and thorough analysis of pull requests (PRs). By minimizing false positives, diffray allows teams to focus on genuine issues, reporting 87 percent fewer irrelevant comments and identifying three times more real problems. Consequently, developers can dramatically reduce their PR review time from an average of 45 minutes to just 12 minutes per week. With seamless integration capabilities for platforms like GitHub, GitLab, and Bitbucket, diffray is particularly beneficial for teams eager to enhance code quality while reducing distractions during the review process.
About OpenMark AI
OpenMark AI is a web application for task-level LLM benchmarking. You describe what you want to test in plain language, run the same prompts against many models in one session, and compare cost per request, latency, scored quality, and stability across repeat runs, so you see variance, not a single lucky output.
The product is built for developers and product teams who need to choose or validate a model before shipping an AI feature. Hosted benchmarking uses credits, so you do not need to configure separate OpenAI, Anthropic, or Google API keys for every comparison.
You get side-by-side results with real API calls to models, not cached marketing numbers. Use it when you care about cost efficiency (quality relative to what you pay), not just the cheapest token price on a datasheet.
OpenMark AI supports a large catalog of models and focuses on pre-deployment decisions: which model fits this workflow, at what cost, and whether outputs are consistent when you run the same task again. Free and paid plans are available; details are shown in the in-app billing section.